
Introduction
We were supporting one of our customers with heterogeneous database migrations of many on-prem Oracle databases to AWS Aurora/Postgres databases. You can find more details about the migration project here. When dealing with the migrations, we identified the need to verify that the target database (the outcome of the migration) does not deviate from the migrated (source) database. Database migration can lead to two types of discrepancies:
- Schema discrepancy is a situation when the schema of the target database accidentally deviates from the schema of the source database. A missing table, a missing foreign key constraint or inconsistent datatype of a table column are examples of schema discrepancy.
- Data discrepancy is a situation when a record in the target database has at least one column value distinct from its counterpart in the source database.
Therefore, we developed a database comparison tool that allows us to automate the validation of the result of the migration. The tool is inspired by several software testing principles. It provides a high degree of confidence which has been achieved with an affordable implementation effort. The tool allows users to compare the source database with the target database and report discovered discrepancies. The validation involves two comparisons:
- Schema comparison allows us to detect schema discrepancies.
- Data comparison allows us to detect data discrepancies.
Each of the two comparisons generates a report where you can see the outcome (PASSED/FAILED) and details of each verification performed. If there are any FAILED verifications, the reports provide a valuable input for the analysis. The following diagram illustrates the functionality of the tool.
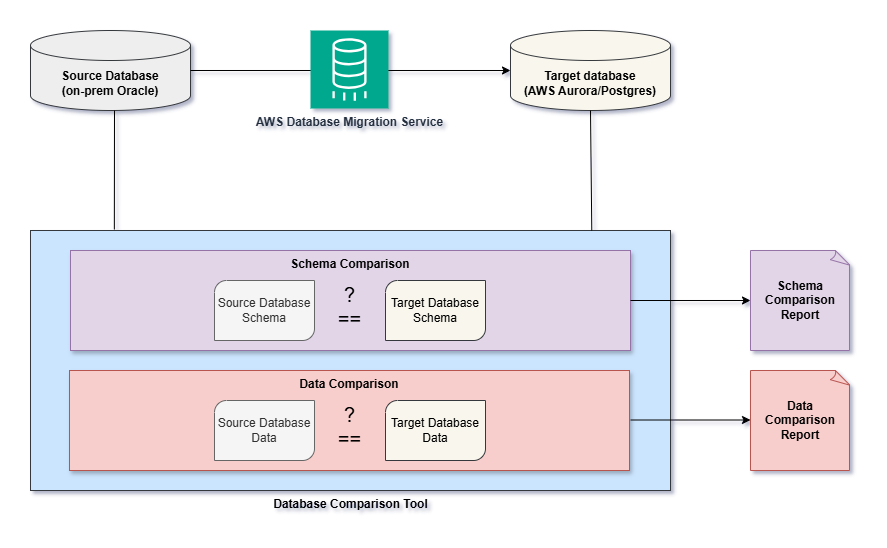
Data Validation Provided by Database Migration Service
AWS Database Migration Service (DMS) provides optional data validation – you can enable it for particular DMS tasks. However, its behavior is somewhat mysterious.
- We have not found any description of how exactly it validates the data.
- Even if the validation fails for one or more tables, the DMS task is presented as successful, and DMS does not provide any details about the reason for the validation error.
- Finally, there were few cases when the outcome of the DMS data validation deviated from the validation result produced by our tool, and a deeper analysis of the concerned data showed that our validation tool was reporting the issue properly.
In a nutshell, our tool seems to provide a higher degree of confidence, plus easier analysis of identified data discrepancies. In addition, the comparison reports generated by our tool can be retained as evidence.
Schema Comparison
There were several motivations to implement the schema validation:
- Even for the most simple migration scenarios, it is extremely easy to make a human error leading to a schema discrepancy. For instance, constructs like indexes and foreign key constraints are typically created after the data migration, so they can easily be forgotten.
- In some cases, the application teams continued with application development simultaneously with the database migration activities. There were few cases when the schema in the source database changed after the generation of the schema DDL for the target database but before the official migration.
- There were some complex migration scenarios for 3rd party software like Adobe Campaign. In these cases, schema DDL provided by the vendor was combined with customizations. The final schema involved more than 100 tables. Some of the tables had tens of columns. In such cases, there was a high risk of schema discrepancies. Automated schema comparison was a natural way to eliminate the risk. The idea of a proprietary database comparison tool was born when dealing with one of these cases.
Schema validation compares the schema of the source database with the schema of the target database. It reports schema discrepancies
- If tables, views, sequences and other schema objects are identified which are present in of the two databases but missing in the other database.
- If there is a table which is inconsistent with its counterpart. For instance, if a column is present in the source database, but missing in the target database, it is reported. If there is a column whose data type in the source database is distinct from its datatype in the target database, it is reported as well. Consistency of indexes and constraints is also verified.
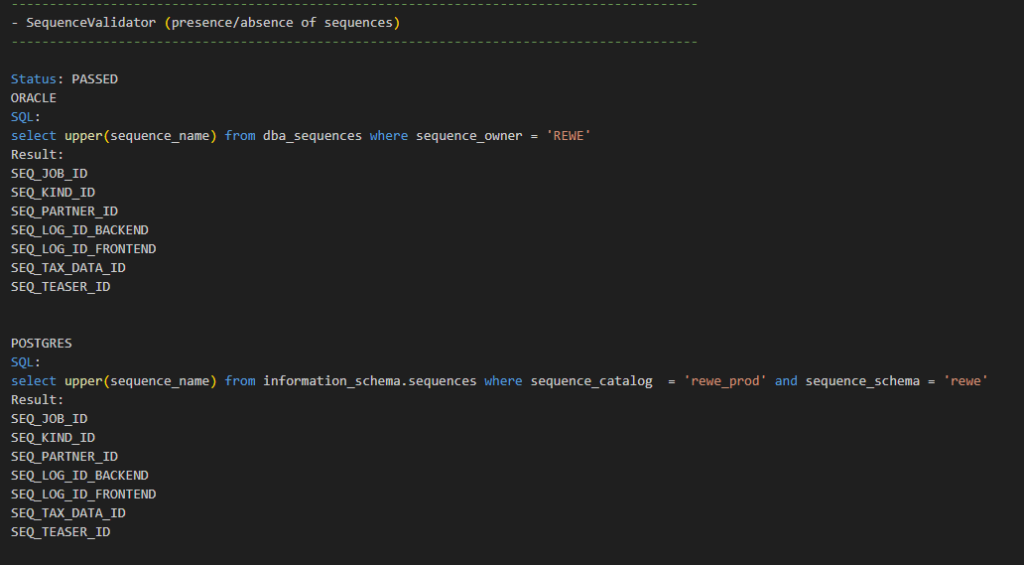
The following screenshots illustrate snippets from a schema comparison report. The first snippet illustrates the outcome of a comparison checking whether all sequences present in the source database are also present in the target database and vice versa. As no discrepancy was detected by this comparison, the outcome of the comparison is PASSED. For every comparison, the report contains:
- Both SQL queries (one retrieving information from the source database, the other retrieving information from the target database)
- The data retrieved by the two SQL queries (the names of sequences in this particular case)
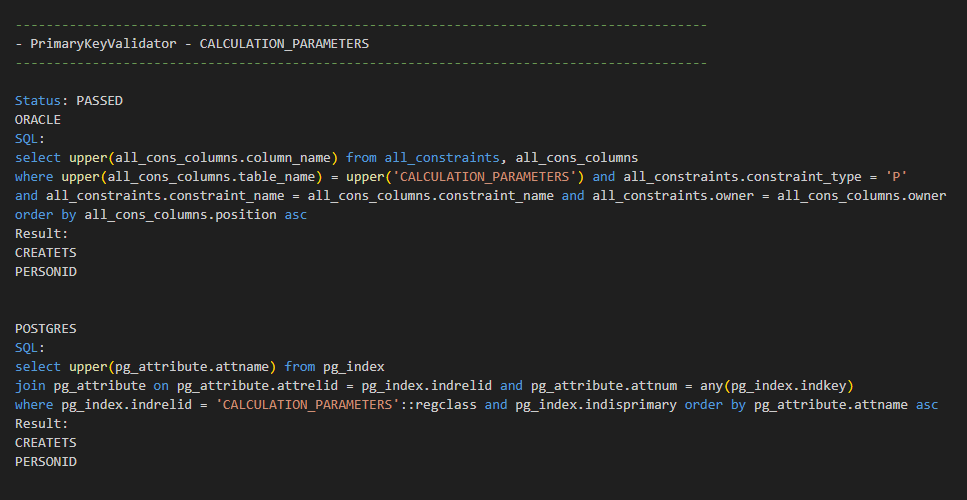
The snippet below illustrates the outcome of comparison checking whether the primary key of a table named CALCULATION_PARAMETERS consists of the same columns in both databases. In this case, there are no SQL statements as the information is retrieved via meta-info API provided by the JDBC driver. The outcome of the comparison is PASSED as the same set of columns was retrieved from both databases.
Data Comparison
Rudimentary data validation can be performed manually for simple schemas with few tables which do not have too many columns. For each table, you can
- Check whether the overall number of records in the source database is the same as in the target database
- Manually compare few records column by column
This manual approach was used during a pilot phase of the project when we were getting familiar with the migration tools, and when we were defining the migration processes and procedures. However, this approach has two major drawbacks:
- It does not scale well for complex schemas with tens or hundreds of tables.
- The degree of confidence it provides is rather low.
Automated data comparison elegantly eliminates both drawbacks. The data validation provided by our tool automates the rudimentary validation process outlined above.
- For each table, it validates the overall number of records.
- It also validates particular columns of each table.
For each column, one or more validations can be applied. The number of validations applied to a column depends on the datatype of the column as well as on whether the column accepts NULL values. Every column validation performs a pair of queries – one in the source database, the other in the target database. If the data is consistent, the result-set of both queries should be identical. Column validations are designed so that they
- Are easy to implement
- Have acceptable execution time even for large tables with millions of records
- Have a solid likelihood of detecting eventual discrepancies
Here is a brief explanation of some column validations provided by our tool:
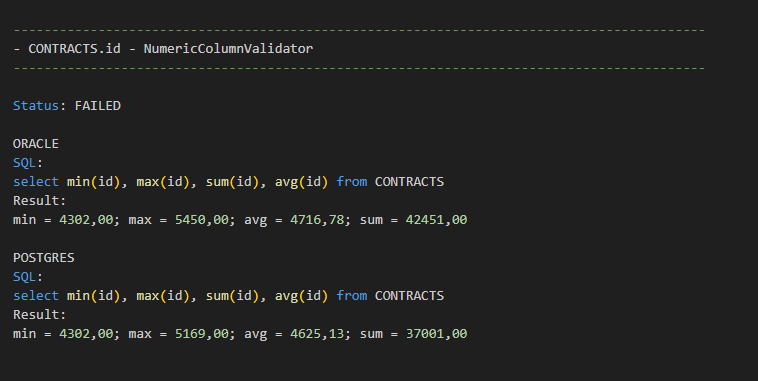
- For numeric columns (both integer and floating point data types), the aggregation functions MIN, MAX, SUM, AVG are used. It is very unlikely that all four aggregation functions would produce exactly the same values for distinct input data. In other words, this is a nice illustration of how a simple query that takes all records into account provides a high degree of confidence for a single column.
- For nullable columns, the overall number or NULL/NOT NULL values is compared. This validation is used as a complement to data type specific validation. In other words, two or more validations are typically applied to nullable columns – at least one data type specific validation, plus NULL values validation. Such a combination of two or more validations applied to a single column increases the degree of confidence provided by our tool.
The following screenshots illustrate snippets from schema comparison report. The first snippet illustrates the outcome of a comparison of a numeric column. As the result-sets of the two SQL queries used by this comparison are not identical, the outcome of this comparison is FAILED.
The snippet below illustrates the outcome of a comparison of a VARCHAR column based on the GROUP BY clause and the COUNT aggregation function applied to the lengths of the VARCHAR values. The outcome of the comparison is PASSED as no discrepancy was found in this case.
Extensibility
The current set of data comparisons provided by the tool supports the vast majority of data types relevant for our migration scenarios. Although it does not support all possible data types, it can be easily extended in terms of new comparisons, and the extensibility concerns both schema comparison and data comparison.
The tool has been designed specifically for Oracle to Postgres migration. In its current form, it cannot be used for other migration scenarios like Oracle to MySQL or Postgres to Oracle. However, with some redesign and rework, it could be made more generic and thus suitable for other migration scenarios. The effort needed for the redesign/rework would most likely not exceed 10–15 MD.
Conclusion
The tool was used to support heterogeneous database migrations of many on-prem Oracle databases to AWS Aurora/Postgres databases. It prevented some migration errors as it detected some schema discrepancies as well as some data discrepancies. With an affordable implementation effort, we achieved:
- High degree of confidence. Achieving the same degree of confidence with manual testing would require an excessive amount of effort and time, with a significant likelihood of human errors. The tool also provides a higher degree of confidence compared to data validation provided by AWS Database Migration Service.
- Acceptable execution time without unnecessary prolongation of downtime. Migration of production databases leads to downtime of the concerned applications. The overall duration of the downtime is determined by several activities, for instance the migration of the data, preparations etc. Database comparison is one of the contributors. Even for large databases with millions of records, the comparison is usually ready within tens of minutes. In other words, the high degree of confidence was achieved with acceptable execution time which did not unnecessarily prolong the overall downtime.
- Easy analysis of detected discrepancies. The reports generated by the tool provide details of what exactly was compared. In case of discrepancies, you see the reason for the failed comparison.
- Auditability. The reports generated by the tool can be retained as evidence of successful verification.
Written by:
Ivan Serváček, DevOps Engineer

